
写该文章的目的,主要是为大家讲解一下:如何利用Python语言实现邮件自动下载以及附件解析功能,下文附上了比较详细的代码,感兴趣的话,可以仔细阅读哦。
开始码代码之前,我们先来了解一下三种邮件服务协议:
1、SMTP协议
SMTP(Simple Mail Transfer Protocol),即简单邮件传输协议。相当于中转站,将邮件发送到客户端。
2、POP3协议
POP3(Post Office Protocol 3),即邮局协议的第3个版本,是电子邮件的第一个离线协议标准。该协议把邮件下载到本地计算机,不与服务器同步,缺点是更易丢失邮件或多次下载相同的邮件。
3、IMAP协议
IMAP(Internet Mail Access Protocol),即交互式邮件存取协议。该协议连接远程邮箱直接操作,与服务器内容同步。
然后介绍一下email包
这个包的中心组件是代表电子邮件消息的“对象模型”。应用程序主要通过在message子模块中定义的对象模型接口与这个包进行交互。应用程序可以使用此API来询问有关现有电子邮件的问题、构造新的电子邮件,或者添加或移除自身也使用相同对象模型接口的电子邮件子组件。也就是说,遵循电子邮件消息及其MIME子组件的性质,电子邮件对象模型是所有提供EmailMessage API的对象所构成的树状结构。
接下来我们通过具体的代码实现一个登录邮箱客户端,下载邮件,解析邮件附件内容的功能。
首先我们需要定义一个邮件解析的类,该类需要三个变量:
1、邮箱所属的imap服务地址;
2、邮箱账号;
3、邮箱密码【注:不同邮箱需要不同的安全策略,例如qq邮箱需要短信验证,获取登录授权码,而不是明文密码去登录远程客户端】
class Email_parse:
def __init__(self,remote_server_url,email_url,password):
# imap服务地址
self.remote_server_url = remote_server_url
# 邮箱账号
self.email_url = email_url
# 邮箱密码
self.password = password
然后定义类中入口函数,登录远程,默认获取第一页所有的邮件。我们获取邮件的主题,并打印出来【不同邮件主题的编码可能不同,二进制需要转码才能正确显示】
def main_parse_Email(self):
"""入口函数,登录imap服务"""
server = imaplib.IMAP4_SSL(self.remote_server_url, 993)
server.login(self.email_url, self.password)
server.select('INBOX')
status,data = server.search(None,"ALL")
if status != 'OK':
raise Exception('read email error')
emailids = data[0].split()
mail_counts = len(emailids)
print("count:",mail_counts)
# 邮件的遍历是按时间从后往前,这里我们选择最新的一封邮件
for i in range(mail_counts - 1, mail_counts - 2, -1):
status, edata = server.fetch(emailids[i], '(RFC822)')
msg = email.message_from_bytes(edata[0][1])
#获取邮件主题title
subject = email.header.decode_header(msg.get('subject'))
if type(subject[-1][0]) == bytes:
title = subject[-1][0].decode(str(subject[-1][1]))
elif type(subject[-1][0]) == str:
title = subject[-1][0]
print("title:", title)
其中,msg变量保存的就是邮件的主体,接下来因为会重复用到msg和tilte,我们将构造一个类函数返回msg和title。
def get_email_title(msg):
subject = email.header.decode_header(msg.get('subject'))
if type(subject[-1][0]) == bytes:
title = subject[-1][0].decode(str(subject[-1][1]))
elif type(subject[-1][0]) == str:
title = subject[-1][0]
print("title:", title)
return title
解析邮件,我们分为两部分,邮件正文【HTML】和附件【xlsx等】,判断有附件,我们就保存到固定的路径下。表格的解析不再赘述了,pandas之类的包足以搞定。
def get_att(msg):
"""获取附件并下载"""
filename = Email_parse.get_email_name(msg)
for part in msg.walk():
file_name = part.get_param("name")
if file_name:
data = part.get_payload(decode=True)
if data != None:
att_file = open('./src/' + filename, 'wb')
att_file.write(data)
att_file.close()
else:
pass
邮件正文内容,我们直接解析html,将文本内容直接保存到.txt文件中,方便读取。
def get_text_from_HTML(msg):
"""获取邮件中的html"""
filename = Email_parse.get_email_name(msg)
current_title = Email_parse.get_email_title(msg)
print("filename:",filename,type(filename))
for part in msg.walk():
if not part.is_multipart():
result = part.get_payload(decode=True)
result = result.decode('gbk')
f = open(f'./src/{current_title}.txt','w')
f.write(result)
f.close()
return result
完整代码如下:
import email
import imaplib
from email.header import decode_header
import pandas as pd
import datetime
class Email_parse:
def __init__(self,remote_server_url,email_url,password):
self.remote_server_url = remote_server_url
self.email_url = email_url
self.password = password
def get_att(msg):
filename = Email_parse.get_email_name(msg)
for part in msg.walk():
file_name = part.get_param("name")
if file_name:
data = part.get_payload(decode=True)
if data != None:
att_file = open('./src/' + filename, 'wb')
att_file.write(data)
att_file.close()
else:
pass
def get_email_title(msg):
subject = email.header.decode_header(msg.get('subject'))
if type(subject[-1][0]) == bytes:
title = subject[-1][0].decode(str(subject[-1][1]))
elif type(subject[-1][0]) == str:
title = subject[-1][0]
print("title:", title)
return title
def get_email_name(msg):
for part in msg.walk():
file_name = part.get_param("name")
if file_name:
h = email.header.Header(file_name)
dh = email.header.decode_header(h)
filename = dh[0][0]
if dh[0][1]:
value, charset = decode_header(str(filename, dh[0][1]))[0]
if charset:
filename = value.decode(charset)
print("附件名称:", filename)
return filename
def main_parse_Email(self):
server = imaplib.IMAP4_SSL(self.remote_server_url, 993)
server.login(self.email_url, self.password)
server.select('INBOX')
status,data = server.search(None,"ALL")
if status != 'OK':
raise Exception('read email error')
emailids = data[0].split()
mail_counts = len(emailids)
print("count:",mail_counts)
for i in range(mail_counts - 1, mail_counts - 2, -1):
status, edata = server.fetch(emailids[i], '(RFC822)')
msg = email.message_from_bytes(edata[0][1])
subject = email.header.decode_header(msg.get('subject'))
if type(subject[-1][0]) == bytes:
title = subject[-1][0].decode(str(subject[-1][1]))
elif type(subject[-1][0]) == str:
title = subject[-1][0]
print("title:", title)
Email_parse.get_att(msg)
Email_parse.get_text_from_HTML(msg)
def get_text_from_HTML(msg):
filename = Email_parse.get_email_name(msg)
current_title = Email_parse.get_email_title(msg)
print("filename:",filename,type(filename))
for part in msg.walk():
if not part.is_multipart():
result = part.get_payload(decode=True)
result = result.decode('gbk')
f = open(f'./src/{current_title}.txt','w')
f.write(result)
f.close()
return result
if __name__ == "__main__":
remote_server_url = 'imap.qq.com'
email_url = "*********@qq.com"
password = "**********"
demo = Email_parse(remote_server_url,email_url,password)
demo.main_parse_Email()
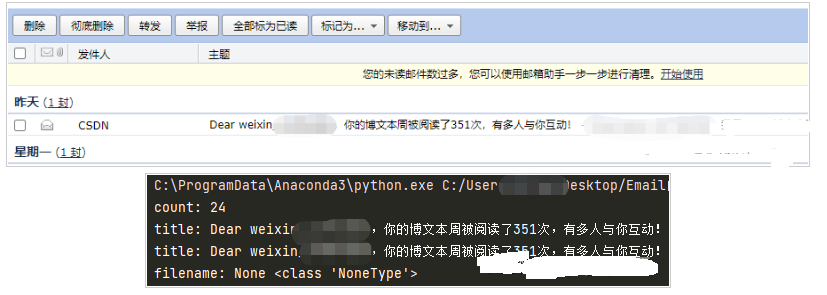
运行结果:
上文就是关于如何利用Python语言实现邮件自动下载以及附件解析功能的详细解答,希望能给各位读者带来更多的帮助。
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/127552.html
这两天和朋友谈到软件测试的发展:这一行的变化确实蛮大,从开始最基础的功能测试,到现在自动化、性能、安全乃至于以后可能出现的大数据测试、AI测试岗位需求逐渐增多。我也在软件测试这行摸爬滚打了十年了,正好有朋友问我:如何快速成为互联网时代优秀的测试工程师呢?趁着最近终于有了些闲余时间,遂总结了下自动化测试的成长线路图和职业必备技能,希望可以帮助各位少走弯路、破茧成蝶、迈向成功。 下面我来分享下自动化测...

Python在自动化办公方面,用处还是比较的大的,如果使用起来的话,其办公的效率会大大的提高。特别是我们在做报表的时候,使用python更加的简洁方便,那么,怎么实现报表自动化呢?我们制作完报表之后,怎么才能够自动发送到邮箱呢?下面给大家详细解答下。 项目背景 作为数据分析师,我们需要经常制作统计分析图表。但是报表太多的时候往往需要花费我们大部分时间去制作报表。这耽误了我们利用大量的时间去...
摘要:年月日,研究人员通过邮件列表披露了容器逃逸漏洞的详情,根据的规定会在天后也就是年月日公开。在号当天已通过公众号文章详细分析了漏洞详情和用户的应对之策。 美国时间2019年2月11日晚,runc通过oss-security邮件列表披露了runc容器逃逸漏洞CVE-2019-5736的详情。runc是Docker、CRI-O、Containerd、Kubernetes等底层的容器运行时,此...
摘要:在这里真心感谢一直在支持我的那几个粉丝,谢谢你们的持续关注点赞。果然,第三个包也是按的步差来的,而为零不变,也不变。函数里面的话就是个循环咯,当条件不满足时就一直加,知道条件满足为止。我每天都会抽时间给我的粉丝解答,给与一些学习资源。 目录 前言 准备工作 分析(x0) 分析(x1) 分析(...
阅读 1217·2023-01-14 11:38
阅读 1232·2023-01-14 11:04
阅读 1035·2023-01-14 10:48
阅读 2690·2023-01-14 10:34
阅读 1317·2023-01-14 10:24
阅读 1182·2023-01-14 10:18
阅读 772·2023-01-14 10:09
阅读 875·2023-01-14 10:02




