
摘要:就是训象人,在上创造新的智慧目录介绍学习路线图我的学习经历的使用案例介绍是基于的机器学习和数据挖掘的一个分布式框架。学习路线图知识点,我已经列在图中,希望帮助其他人更好的了解。
Hadoop家族系列文章, 主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括,YARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hue等。
从2011年开始,中国进入大数据风起云涌的时代,以Hadoop为代表的家族软件,占据了大数据处理的广阔地盘。开源界及厂商,所有数据软件,无 一不向Hadoop靠拢。Hadoop也从小众的高富帅领域,变成了大数据开发的标准。在Hadoop原有技术基础之上,出现了Hadoop家族产品,通 过“大数据”概念不断创新,推出科技进步。
作为IT界的开发人员,我们也要跟上节奏,抓住机遇,跟着Hadoop一起雄起!
关于作者:
转载请注明出处:
http://blog.fens.me/hadoop-mahout-roadmap/

前言
Mahout是Hadoop家族中与众不同的一个成员,是基于一个Hadoop的机器学习和数据挖掘的分布式计算框架。Mahout是一个跨学科产品,同时也是我认为Hadoop家族中,最有竞争力,最难掌握,最值得学习的一个项目之一。
Mahout为数据分析人员,解决了大数据的门槛;为算法工程师,提供基础的算法库;为Hadoop开发人员,提供了数据建模的标准;为运维人员,打通了和Hadoop连接。
Mahout就是训象人,在Hadoop上创造新的智慧!
目录
Mahout 是基于Hadoop的机器学习和数据挖掘的一个分布式框架。Mahout用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题。
根据”Mahout In Action”书中的介绍,Mahout实现3大类算法, 推荐(Recommendation),聚类(Clustering),分类(Classification)。
下文介绍的学习路线图,将以”Mahout In Action”书中思路展张。
2. Mahout学习路线图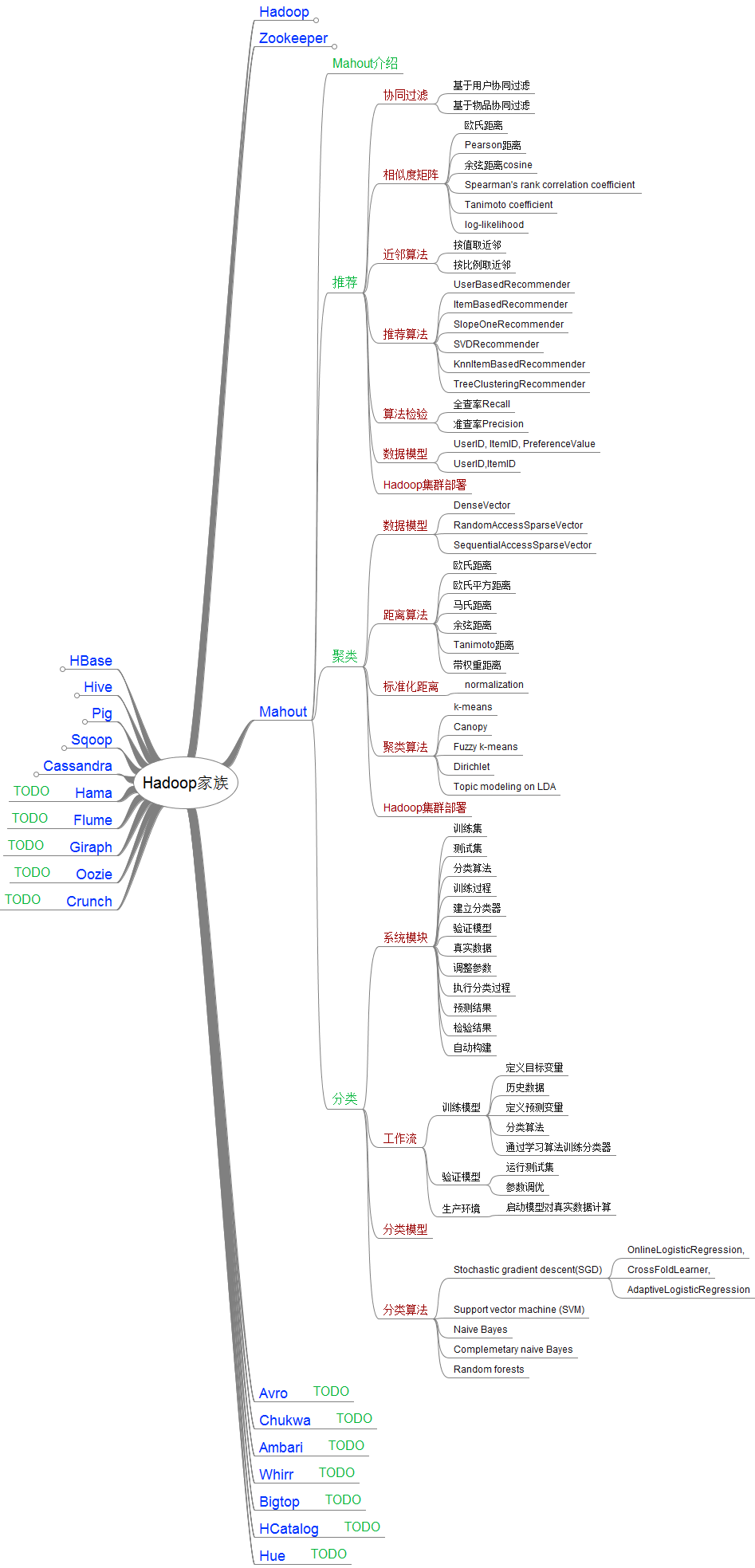
Mahout知识点,我已经列在图中,希望帮助其他人更好的了解Mahout。
接下来,是我的学习经历,谁都没有捷径。把心踏实下来,就不那么难了。
3. 我的学习经历之前,大概花了半年的时间,专门研究过Mahout,当时Mahout的资料非常少,中文资料更是仅仅几篇。直到发现了“Mahout In Action”如获至宝,开始反复地读。先不着急上手去做什么,一遍一遍地读。直到读完3遍,心理才有了一点把握。
从“推荐”算法开始,UserCF, ItemCF。 记得第一次在公司给小组讲的时候,还设计了一份问卷,我列出了10个网站,(其中6个IT大站,2个个人blog,2个社交类社区),分别让大家去投票,0-5分,0为不知道,1-5为对网站喜爱程序。
问卷结果格式:
user1, website1, 5
user1, website2, 2
user1, website3, 4
user2, website3, 2
user3, website3, 5
user4, website3, 0
…..
通过这个问卷来模拟尝试Mahout的推荐模型!计算的结果对大家来说,都是比较奇怪。为什么会有这样的推荐呢。 然后,深入Mahout源代码,看算法的实现,知道了相似度矩阵,距离算法,推荐算法,模型验证等,不同业务要求,不同的算法调用,对结果都是有影响的。 把书中所有的的概念,关键词都整理过(可惜当时没写博客)。整整花了3个月,每天12个小时的强度,把推荐部分完整地学下来了。
然后,应用到实际业务中。我的任务是做“职位推荐”,我只有用户浏览职位,收藏职位,申请职位的行为数据。
第一次尝试,直接套用推荐模型,但结果非常之差。
出现问题的原因是有2点:
修改方案:
1. 对用户行为数据集进行过滤,只计算最近半年内的用户行为。
2. 对结果集进行过滤,排除过期的职位。
3. 分别用不同的算法模型计算(我记得Tanimoto的Item Base结果较好)
对于推荐结果有了大幅度的提升。故事到此就结束了!虽然我还做了更多的事情,不过这个产品由于公司结构性调整,最终没有上线。(程序员的悲哀!)
聚类模型,我把这个算法 应用在网站用户的活跃度分析。假设一个网站,注册用户1000W,每天登陆的1W。我们想了解一下,未登陆的999W用户有什么特点!!用到Mahout 的k-means和Canopy做聚类,假设1000W的用户可能可以划分为5个大的群体。最后我们得到了一个结果,分享到了团队。故事又到此结束了。 (实现就是这么悲哀!)
分类模型,我尝试着用Native Bayes对我的个人邮件进行垃圾分类。按机器学习的操作流程,历史数据健分词后,训练分类器,每天时时的数据通过分类器进行判断。整个自动化过程都已经完成。故事又结束了!(接受现实吧。)
其实还有一些,我争取都整理出来。
Mahout是有一定的学习门槛,而且需要跨学科的知识。只要坚持学习,没有跨不过的鸿沟!乐观努力!
4. Mahout的使用案例已经整理成文章的案例
正在准备更多的案例…..
相关文章:
Hadoop家族产品学习路线图
转载请注明出处:
http://blog.fens.me/hadoop-mahout-roadmap/
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/3812.html
摘要:本文为家族开篇,家族学习路线图目录家族产品家族学习路线图家族产品截止到年,根据的统计,家族产品已经达到个接下来,我把这个产品,分成了类。家族学习路线图下面我将分别介绍各个产品的安装和使用,以我经验总结我的学习路线。 Hadoop家族系列文章, 主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, ...
摘要:某些部分的实现直接创建在之上,这就使得其具有进行大数据处理的能力,也是较大的优势所在。在目录下执行命令,检测系统是否安装成功。运行里自带的算法,,这里启动后遇到了一点问题,提示,后来参考这篇日志解决。 转载请注明出处: http://hanlaiming.freetzi.com/?p=144 一、介绍Mahout Mahout是Apache下的开源机器学习软件...
摘要:目前的正式头衔为数据科学部门主管,目前他正专注投身于名为的开源机器学习项目当中。作为当中实现机器学习模式创建的传统途径,已经走到了发展道路的尽头,指出。从机器学习的角度来看,拥有大量极具吸引力的特性,他表示。 Hadoop软件供应商Cloudera去年收购了一家总部位于伦敦的新兴企业Myrrix——但在此之后无论是买家还是卖家在机器学习技术方面都开始归于沉寂。不过无论如何,Myrrix公司的...
摘要:大家好,我是冰河有句话叫做投资啥都不如投资自己的回报率高。马上就十一国庆假期了,给小伙伴们分享下,从小白程序员到大厂高级技术专家我看过哪些技术类书籍。 大家好,我是...
摘要:免费下载地址在用户名与密码都是具体下载目录在年资料月日解析序列文件并可视化输出下载方法见是读取任务序列文件到一个变量里面,可以启动调试模式进行变量查看是读取序列文件,并解析其和,然后可视化输出,所谓可视化输出是指不是乱码的输出。 Hadoop版本:1.0.4,jdk:1.7.0_25 64bit。 在进行mahout算法分析的时候有时会遇到算法最后的输出文件是序列文件的情况下,这样就不能直接...

阅读 1509·2021-09-26 10:00
阅读 2754·2021-09-06 15:00
阅读 3316·2021-09-04 16:40
阅读 2175·2019-08-30 15:44
阅读 531·2019-08-30 10:59
阅读 1740·2019-08-29 18:34
阅读 3491·2019-08-29 15:42
阅读 2107·2019-08-29 15:36

















