
摘要:如今在机器学习中突出的人工神经网络最初是受神经科学的启发。虽然此后神经科学在机器学习继续发挥作用,但许多主要的发展都是以有效优化的数学为基础,而不是神经科学的发现。
开始之前看一张有趣的图 - 大脑遗传地图:
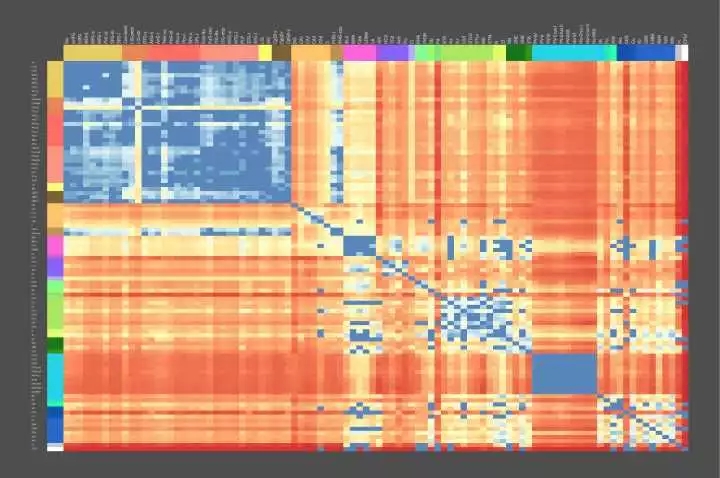
Figure 0. The Genetic Geography of the Brain - Allen Brain Atlas
成年人大脑结构上的基因使用模式是高度定型和可再现的。 Figure 0 中所示的动态热图表示跨个体的这种图案化模式的共同结构,特别是一些介于解剖区域对(pairs of anatomic regions)之间差异表达的基因数目,在我们的实验测量中,有5/6的大脑中发现了类似共同的模式。 热红色阴影代表在其转录调节中非常不同的脑区域,而较冷的蓝色阴影代表高相似性的区域。
先看这张图的用意是在于让读者了解目前大脑、神经科学的前沿,人类不仅具有了解全部大脑基本功能的能力,并且已经具备将各功能区域映射到自身遗传物质编码上的能力。不仅如此,更多先进的探测技术已经能让人们记录下更详细的神经元内部的活动(dynamics),这使得对大脑内部计算结构的分析成为可能,上图所示内容凝结了众多科学家的努力,相信一定是21世纪最伟大的科学突破之一。
说明:
1. 翻译这篇文章出于学习目的,有翻译或者理解有误的地方还望大家多多指教;
2. 本文可以任意转载,支持知识分享,但请注明出处或附上原文地址;
3. 文章中所有的引用都在本文内嵌链接中可以找到,该论文有488篇引用!
4. 翻译将进行连载,这是系列的第一部分,对应论文第一章;
Standing on the shoulders of giants, to touch the hands of "god".
引言
计算神经科学专注于计算的详细实现,研究神经编码、动力学和电路。然而,在机器学习中,人工神经网络倾向于避开较精确设计的代码,动力学或电路,有利于成本函数的强力优化(暴力搜索),通常使用简单和相对均匀的初始架构。在机器学习中,近期的两个发展方向创造了连接这些看似不同观点的机会。首先,使用结构化体系架构,包括用于注意力机制,递归和各种形式的短期和长期存储器存储的专用系统(Specialized System)。第二,成本函数和训练过程变得更加复杂,并且随着时间的推移而变化。在这里我们根据这些想法思考大脑。我们假设(1)大脑优化成本函数,(2)成本函数是多样的且在不同的发展阶段大脑不同位置的成本函数是不同的,和(3)优化操作是在一个由行为预先架构好的、与对应计算问题相匹配的框架内执行。为了支持这些假设,我们认为通过多层神经元对可信度分配(Credit Assignment)的一系列实现是与我们当前的神经电路知识相兼容的,并且大脑的一些专门系统可以被解释为对特定问题实现有效的优化。通过一系列相互作用的成本函数,这样非均匀优化的系统使学习过程变得数据高效,并且较精确地针对机体的需求。我们建议一些神经科学的研究方向可以寻求改进和测试这些假设。
这里提到的相互作用的成本函数非常有趣,在目前的深度学习领域,使用多目标函数的学习任务包括multi-task learning,transfer learning,adversarial generative learning等,甚至一些带约束条件的优化问题都可以一定程度上看做是多目标函数的。(“目标函数”是旨在最小化成本的函数,论文中使用成本函数,而所有的智能学习过程都是旨在降低各种成本函数值,比较普遍地人们会使用“信息熵”来作为量化标准,那么学习就可以看做是降低不确定性的行为)更有趣的是怎么相互作用?相互作用的目标函数对学习过程有怎样的帮助?
1. 介绍
今天的机器学习和神经科学使用的并不是同一种“语言”。 脑科学发现了一系列令人眼花缭乱的大脑区域(Solari and Stoner, 2011)、细胞类型、分子、细胞状态以及计算和信息存储的机制。 相反,机器学习主要集中在单一原理的实例化:函数优化。 它发现简单的优化目标,如最小化分类误差,可以导致在在多层和复现(Recurrent)网络形成丰富的内部表示和强大的算法能力(LeCun et al., 2015; Schmidhuber, 2015)。 这里我们试图去连接这些观点。
如今在机器学习中突出的人工神经网络最初是受神经科学的启发(McCulloch and Pitts, 1943)。虽然此后神经科学在机器学习继续发挥作用(Cox and Dean, 2014),但许多主要的发展都是以有效优化的数学为基础,而不是神经科学的发现(Sutskever and Martens,2013)。该领域从简单线性系统(Minsky and Papert, 1972)到非线性网络(Haykin,1994),再到深层和复现网络(LeCun et al., 2015; Schmidhuber, 2015)。反向传播误差(Werbos, 1974, 1982; Rumelhart et al., 1986)通过提供一种有效的方法来计算相对于多层网络的权重的梯度,使得神经网络能够被有效地训练。训练神经网络的方法已经改进了很多,包括引入动量的学习率,更好的权重矩阵初始化,和共轭梯度等,发展到当前使用分批随机梯度下降(SGD)优化的网络。这些发展与神经科学并没有明显的联系。
然而,我们将在此论证,神经科学和机器学习都已经发展成熟到了可以再次“收敛”(交织)的局面。 机器学习的三个方面在本文所讨论的上下文中都显得特别重要。 首先,机器学习侧重于成本函数的优化(见Figure 1)。
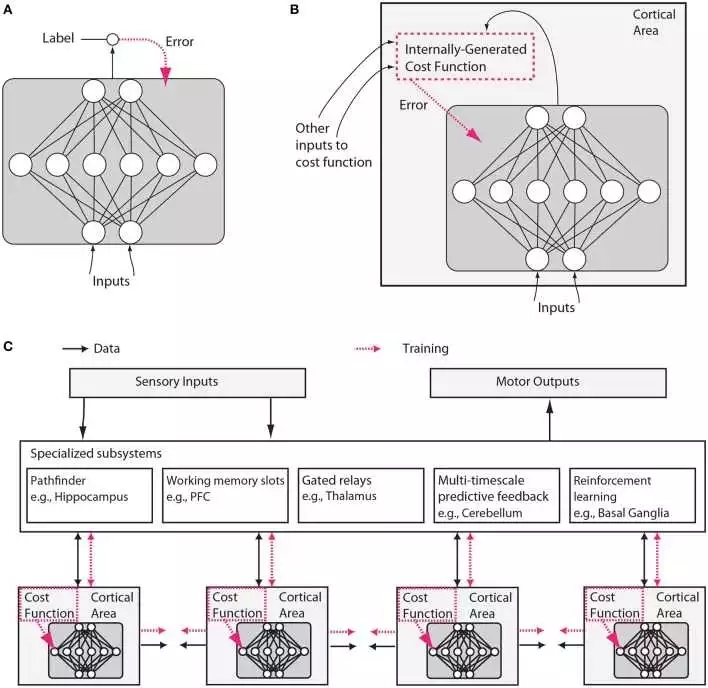
Figure 1. 传统人工神经网络和类脑神经网络设计之间的假设差异。 (A)在常规深度学习中,监督训练基于外部提供的标记数据。 (B)在大脑中,网络的监督训练仍然可以通过对误差信号的梯度下降发生,但是该误差信号必须来自内部生成的成本函数。这些成本函数本身是由遗传基因和后天学习所指定的神经模块计算而来。内部生成的成本函数创建heuristics(这个实在不好翻译,“启发”有些抽象,类似于元信息,大家意会吧),用于引导更复杂的学习。例如,识别面部的区域可以首先使用简单的heuristic来训练以来检测面部,这种heuristic就比如是在直线之上存在两个点,然后进一步训练以使用来自无监督学习的表示结合来自其他与社交奖励处理相关的大脑区域的错误信号来区分显著的面部表情。 (C)内部生成的成本函数和错误驱动的神经皮质深层网络经过训练形成包含几个专门系统的较大架构的一部分。虽然可训练皮层区域在这里被示意为前馈神经网络,但是LSTM或其他类型的recurrent网络可能才是更较精确的比喻,并且许多神经元和网络性质例如神经脉冲、树突计算、神经调节、适应和稳态可塑性、定时依赖性可塑性、直接电连接、瞬时突触动力、兴奋/抑制平衡、自发振荡活动、轴突传导延迟(Izhikevich, 2006)等将影响这些网络学习的内容和方式。
这里说到的“来自无监督学习的表示”可以用人工智能里的知识表示来理解,来自大脑其他区域的错误信号也是一种表示,所以他们可以结合。深度学习中我们用实值张量来表示知识,个人认为knowledge representation是智能形成最基础的核心之一。C中描述的结构与《On Intelligence》中作者提到的”柱状体“神经网络非常类似。结尾的一大串神经动力学名词真是又一次让我深深感受到自己的无知...
第二,近来在机器学习中的工作开始引入复杂的成本函数:在层和时间上不一致的成本函数,以及由网络的不同部分之间的交互产生的那些函数。 例如,引入低层的时间相干性(空间上非均匀成本函数)的目标改进了特征学习(Sermanet and Kavukcuoglu, 2013),成本函数计划(时间上非均匀成本函数)改进了泛化能力(Saxe et al., 2013; Goodfellow et al., 2014b; Gülçehre and Bengio, 2016)以及对抗网络 - 内部交互作用产生的成本函数的一个例子 - 允许生成式模型基于梯度训练(Goodfellow et al., 2014a)。 更容易训练的网络正被用于提供“提示”,以帮助引导更强大的网络的训练(Romero et al., 2014)。
第三,机器学习也开始多样化进行优化的架构。 它引入了具有多重持久状态的简单记忆细胞(Hochreiter and Schmidhuber, 1997; Chung et al., 2014),更复杂的基本计算结构单元如“胶囊”和其他结构(Delalleau and Bengio, 2011; Hinton et al., 2011; Tang et al., 2012; Livni et al., 2013),内容可寻址性(Graves et al., 2014; Weston et al.,2014)和位置可寻址存储器(Graves et al., 2014),另外还有指针 (Kurach et al., 2015)和硬编码算术运算(Neelakantan et al., 2015)。
这三个想法到目前为止在神经科学中没有受到很多关注。 因此,我们将这些想法形成为关于大脑的三个假设,检查它们的证据,并且描绘可以如何测试它们的实验。 但首先,我们需要更准确地陈述假设。
1.1 假设1 – 大脑进行成本函数优化
连接两个领域的中心假设是,像许多机器学习系统一样,生物系统能够优化成本函数。成本函数的想法意味着大脑区域中的神经元可以以某种方式改变它们的属性,例如它们的突触的属性,使得它们在做任何成本函数定义为它们的角色时更好。人类行为有时在一个领域中达到最优,例如在运动期间(Körding, 2007),这表明大脑可能已经学习了较佳策略。受试者将他们的运动系统的能量消耗最小化(Taylor and Faisal, 2011),并且使他们的身体的风险和损害最小化,同时较大化财务和运动获益。在计算上,我们现在知道轨迹的优化为非常复杂的运动任务提出了非常不错的解决方案(Harris and Wolpert, 1998; Todorov and Jordan, 2002; Mordatch et al., 2012)。我们认为成本函数优化更广泛地发在大脑使用的内部表示和其他处理过程之中。重要的是,我们还建议这需要大脑在多层和recurrent网络中具备有效的信用分配(credit assignment,感觉翻译成中文还是有些奇怪)机制。
1.2 假设2 – 不同的发展阶段中不同大脑区域的成本函数不同
第二个假设的另一种表达是:成本函数不需要是全局的。 不同脑区域中的神经元可以优化不同的事物,例如,运动的均方误差、视觉刺激中的惊喜或注意分配。 重要的是,这样的成本函数可以在局部大脑区域生成。 例如,神经元可以局部评估其输入的统计模型的质量(Figure1B)。 或者,一个区域的成本函数可以由另一个区域生成。 此外,成本函数可以随时间改变,例如,神经网络先指导小孩早期理解简单的视觉对比度,稍后再进行面部识别。 这可以允许发展中的大脑根据更简单的知识来引导更复杂的知识。 大脑中的成本函数是非常复杂的,并且被安排成在不同地区和不同发展之间变化。
1.3 假设3 – 专门系统提供关键计算问题上的高效解
第三个认识是:神经网络的结构很重要。信息在不同大脑区域流动的模式似乎有根本性差异的,这表明它们解决不同的计算问题。一些脑区是高度recurrent的,可能使它们被预定为短期记忆存储(Wang, 2012)。一些区域包含能够在定性不同的激活状态之间切换的细胞类型,例如响应于特定神经递质的持续发射模式与瞬时发射模式(Hasselmo, 2006)。其他区域,如丘脑似乎有来自其他区域的信息流经它们,也许允许他们确定信息路由(Sherman, 2005)。像基底神经节的区域参与强化学习和分离决定的门控(Doya, 1999; Sejnowski and Poizner,2014)。正如每个程序员所知,专门的算法对于计算问题的有效解决方案很重要,并且大脑可能会很好地利用这种专业化(Figure1 C)。
这些想法受到机器学习领域的进展的启发,但我们也认为大脑与今天的机器学习技术有很大的不同。特别是,世界给我们一个相对有限的信息量以让我们可以用于监督学习(Fodor and Crowther, 2002)。有大量的信息可用于无人监督的学习,但没有理由假设会存在一个通用的无监督算法,无论多么强大,将按人们需要知道的顺序较精确学习人类需要知道的事情。因此,从进化的角度来看,使得无监督学习解决“正确”问题的挑战是找到一系列成本函数,其将根据规定的发展阶段确定性地建立电路和行为,使得最终相对少量的信息足以产生正确的行为。例如,一个成长中的鸭子跟随(Tinbergen, 1965)其父母的行为印记模板,然后使用该模板来生成终级目标,帮助它开发其他技能,如觅食。
根据上述内容和其他研究(Minsky, 1977; Ullman et al., 2012),我们认为(suggest)许多大脑的成本函数产生于这样的内部自举过程。事实上,我们提出生物发展和强化学习实际上可以程序化实现生成一系列成本函数,较精确预测大脑内部子系统以及整个生物体面临的未来需求。这种类型的发展程序化地引导生成多样化和复杂的成本函数的内部基础设施,同时简化大脑的内部过程所面临的学习问题。除了诸如家族印记的简单任务之外,这种类型的引导可以扩展到更高的认知,例如,内部产生的成本函数可以训练发育中的大脑正确地访问其存储器或者以随后证明有用的方式组织其动作。这样的潜在引导机制在无监督和强化学习的背景下运行,并且远远超出当今机器学习、人工智能课程学习的理念(Bengio et al.,2009)。
这段是至今我所看过的人工智能文献里最精彩的部分。
本文的其余部分,我们将阐述这些假设。 首先,我们将认为局部和多层优化,出乎意料地与我们所知道的大脑兼容。 第二,我们将认为成本函数在大脑区域和不同时间的变化是不同的,并且描述了成本函数如何以协调方式交互以允许引导复杂函数。 第三,我们将列出一系列需要通过神经计算解决的专门问题,以及具有似乎与特定计算问题匹配的结构的脑区域。 然后,我们讨论上述假设的神经科学和机器学习研究方法的一些影响,并草拟一组实验来测试这些假设。 最后,我们从演化的角度讨论这个架构。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4680.html
摘要:就像在权重扰动中,而不同于串扰的是,最小的全局协调是必须的每个神经元仅需要接收指示全局成本函数的反馈信号。在深度强化学习中比如可否使用不可微分的目标函数呢值得探索相反,反向传播通过基于系统的分层结构计算成本函数对每个权重的灵敏度来工作。 2. 大脑能够进行成本函数优化许多机器学习方法(如典型的监督式学习)是基于有效地函数优化,并且,使用误差的反向传播(Werbos, 1974; Rumelh...
摘要:例如,是一些神经元的特征,其中突触权重变化的符号取决于突触前后的较精确至毫秒量级相对定时。,是大脑自身调整其神经元之间的连接强度的生物过程。从他博士期间就开始研究至今,目前可以说深度学习占领着机器学习的半壁江山,而则是深度学习的核心。 上次说到误差梯度的反向传播(Backpropagation),这次咱们从这继续。需要说明的是,原文太长,有的地方会有些冗长啰嗦,所以后面的我会选择性地进行翻译...
摘要:根据百度的说法,这是全球首次将深度学习领域技术应用在客户端,独创了深度神经网络查杀技术。在过去,吴恩达说,百度用神经网络来帮助侦测广告。 吴恩达拿起他的手机,打开了脸优 app。他现在正位于硅谷公司的研究室。在办公桌边吃饭,谈话内容很自然地也涉及到人工智能。他是百度的首席科学家,同时也是斯坦福大学计算机系的教授。在其他搜索引擎仍在发展时,他就曾帮助谷歌启动了脑计划,现在他在百度从事相似的人工...

阅读 1846·2021-11-18 10:02
阅读 2337·2021-11-15 11:38
阅读 2841·2019-08-30 15:52
阅读 2420·2019-08-29 14:04
阅读 3386·2019-08-29 12:29
阅读 2240·2019-08-26 11:44
阅读 1151·2019-08-26 10:28
阅读 1000·2019-08-23 18:37




