



























































日志分析
在线咨询
UES 基于开源分布式搜索和分析引擎 Elasticsearch 构建,提供开箱即用的分析能力。客户可以基于 UES 快速构建起 ELK 日志分析架构,即使用 Beats 作为日志采集器,采集各个服务器节点上的日志数据,经过 Logstash 解析、过滤后,汇集至 UES 集群存储,然后借助 Kibana 的可视化分析能力构建分析看板,高效的进行可视化日志分析工作。如果日志规模庞大,可以在上述架构中引入消息队列 UKafka,确保持续稳定的数据传输和处理。

企业采购季

GPU算力特惠

量化交易主机

OpenClaw

原生住宅IP

中国台湾特惠

中国香港特惠

越南特惠专区

推荐有礼

企业采购季
原生住宅IP
GPU算力特惠

快杰主机特惠

全球专线服务

托管/混合云

私有云

轻量专题活动

CDN特惠

短信特惠促销

一带一路专区

北美算力专区
中国台湾特惠
中国香港特惠
越南特惠专区
OpenClaw
量化交易主机

跨境电商专区

游戏联机服务器

UCloud大数据生态全面支持集数据采集、数据存储、数据分析和数据应用为一体的大数据应用场景,助力企业快速构建大数据处理体系,实现商业目标。




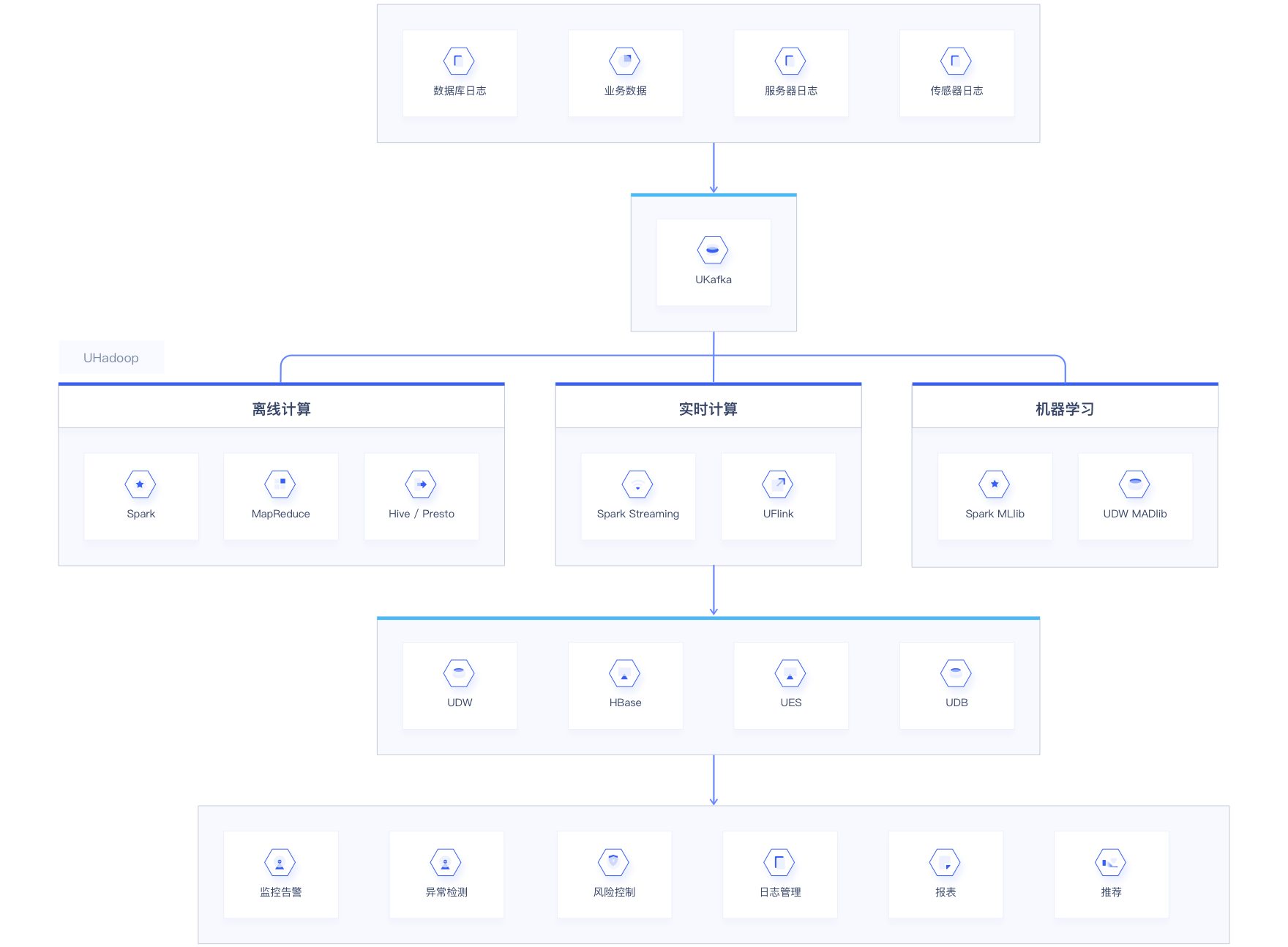
1
用户通过Flume/DataX/Logstash等工具把日志数据、业务数据收集到UKafka中,UKafka中的数据可以给实时计算使用,或转存到HDFS、UES、HBase、UDW等存储系统中做离线分析和数据挖掘使用;
2
实时计算可以通过UFlink、UHadoop中的Spark Streaming在UKafka实时读取数据,进行实时ETL、实时分析、实时训练;
3
离线计算可以通过Hive、Spark 、MapReduce进行数据清洗分析;
4
计算结果数据可以存储在UDW、HBase、UES、MySQL等存储系统中,以支撑个性化推荐、报表、风控、监控等业务使用。










